I Spent $15 Taking an AI Agent from Idea to Production-Ready. Here's Everything I Learned.
AI agents are a black box.
Not because the technology is inherently mysterious. The people selling it want it to feel that way. Everyone is screaming: we can do this, you can do that, connect everything, automate anything. The demos are polished. The promises are big. And most people nod along, trust the tools they've been handed, and hope for the best.
But here's something I've learned from my work at NoCodeLab: hope is not a system design. And blind trust in a tool you don't understand is not a strategy. It's a liability.
My job is to work with these tools. Not just use them. Understand them, challenge them, break them, and eventually teach other people how to use them properly. So when I decided to take an agent idea all the way from concept to something production-ready, I didn't start building. I went back to first principles.
I read. I researched. I worked through the Anthropic documentation, which, if you've ever tried, reads like a never-ending encyclopedia that keeps adding new chapters while you're still on page three. I studied how other teams had structured agent pipelines, what had gone wrong for them, and what decisions they wished they'd made earlier. I tested things. Some of them worked. Some of them didn't. And eventually, from all of that, I built something I'm now calling the Agent Requirement Document: an ARD.
This article is about what that document is, why it exists, what I actually built with it, and what the entire experience cost me. Not just in money, but in clarity.
Why Most People Build Agents Wrong
Here is what building an AI agent looks like for most people:
They have an idea. They open Claude, or GPT, or whatever tool they're using. They start prompting. Something half-works. They keep tweaking. They add a tool. They connect an API. Things get tangled. They rebuild from scratch. They run out of API credits before they've figured out why it keeps failing. Months later, they have something that sort of works in a demo but falls apart with real users.
I've watched this happen. I've been part of conversations where someone has burned hundreds of dollars on credits testing a pipeline that was architecturally broken from the start. Not because they weren't smart, but because they started building before they'd finished thinking.
The problem isn't the technology. The problem is the absence of a spec.
In software development, you wouldn't build a product without a requirements document. You wouldn't start engineering work without agreeing on what "done" looks like. You wouldn't ship without defining what the tool does and, critically, what it doesn't do.
But with AI agents, people skip all of that. They move fast. They iterate chaotically. And they pay for it later.
What an Agent Requirement Document Actually Is
An ARD is a cross-functional product spec for your agent. It's a document you write before you build: before you touch a system prompt, before you configure a tool, before you make a single API call.
It answers every question that will eventually bite you if you leave it unanswered.
What does this agent do, precisely? Not broadly. Step by step, from the moment a user gives it an input to the moment it returns an output. What happens in between? Who does what? In what order?
Which tools does it need, and what rights should those tools have? This is where most people are completely undisciplined. They give their agent everything and restrict nothing. But an agent with write access to something it only needs to read is an agent waiting to cause a problem. Every tool permission should be a deliberate decision.
What does it cost to run? Per run, per day, at scale. If you don't model this before you build, you will discover it in the worst possible way, usually after your first traffic spike. A cost model is not optional. It's part of the design.
What are the input and output contracts for each agent? If your pipeline has multiple agents talking to each other (and it should, for anything non-trivial), each one needs to know exactly what it will receive and exactly what it must return. A mismatch between one agent's output format and another agent's expected input is one of the most common, most frustrating, and most preventable failures in multi-agent systems.
What are the escalation paths? What does each agent do when something goes wrong? When the data is incomplete, when a third-party API fails, when the input is malformed? "I'll handle that later" is not an escalation path. It's a production incident waiting to happen.
What does this tool explicitly NOT do? I know this sounds like it should be obvious. It isn't. A clear boundary statement is one of the most valuable things you can write: for your users, for your team, and for yourself when scope creep starts knocking.
What does "done" look like? Not "it works." Done. Business readiness, agent readiness, infrastructure readiness. A definition you can check against, not a feeling you're chasing.
The Agent I Built
The ARD I wrote was for a NoCodeLab Marketing Campaign Agent.
The concept: a user inputs a website URL and the agent generates a complete, ready-to-post social media campaign: LinkedIn copy, an X thread, an Instagram caption, and a branded Canva visual asset, all analysed from the target website and aligned to the brand.
It sounds simple. It isn't.
The architecture
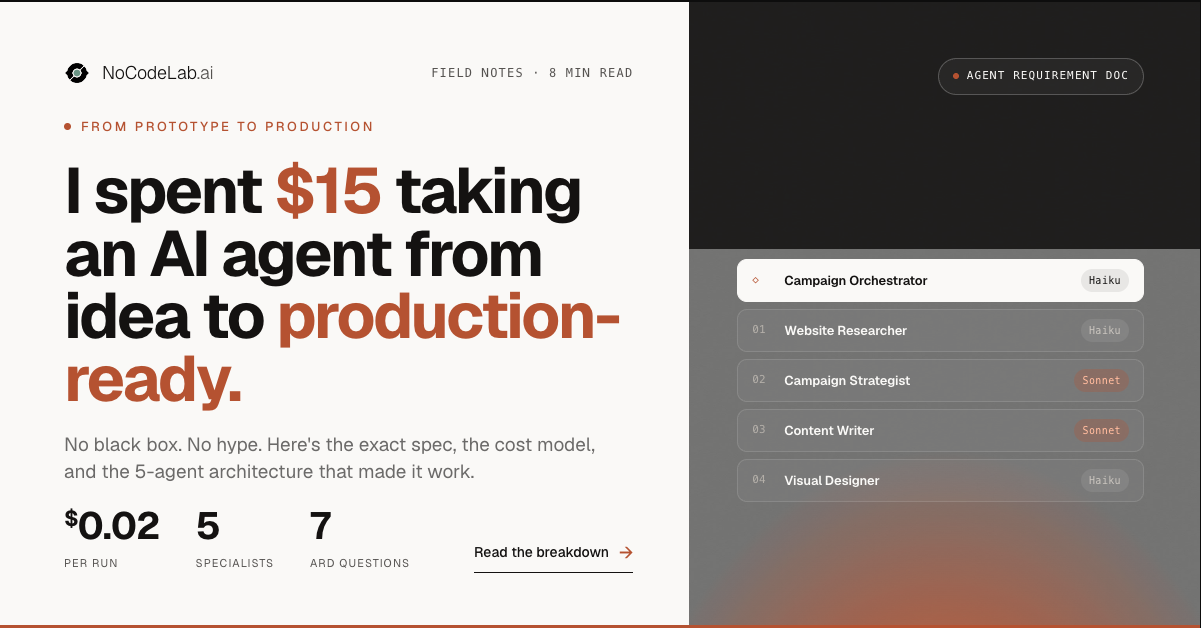
The pipeline runs five agents:
Campaign Orchestrator is the coordinator. It receives the URL, delegates every task, and synthesises the final output. It produces nothing itself. Its sole job is sequencing, routing, and staying within budget. I gave it an explicit rule: you will not write any copy or create any visuals yourself. That constraint matters. Orchestrators that start doing content work create unpredictable pipelines.
Website Researcher receives the URL, uses Tavily to crawl up to five pages, and returns a structured Research Brief with seven fields: business name, what they do, target audience, key value propositions, tone of voice, existing messaging, and notable visual style. It has an explicit input error it returns if the URL is unreachable, and an explicit escalation threshold: if it can't populate at least four of seven fields with reasonable confidence, it flags rather than guesses.
Campaign Strategist takes the Research Brief and builds a campaign strategy: the campaign angle, three key messages, platform-specific directions for LinkedIn, X, and Instagram, a visual mood described in three adjectives, and a CTA. One constraint I built in deliberately: it cannot recommend more than one campaign angle per run. Focus is a product decision, not a prompt suggestion.
Content Writer takes the strategy and writes platform-native copy for all three channels. Not the same post reformatted three times. Each piece is written for how people actually consume content on that platform. The LinkedIn post has a hook, short paragraphs, and 3-5 hashtags at the end. The X thread is 3-5 tweets each under 280 characters, numbered, with the first tweet standing alone as a shareable unit. The Instagram caption has a punchy opener, a line break before the hashtags, and 15-20 tags mixing broad and niche.
Visual Designer takes the campaign strategy (particularly the visual mood and campaign angle) and the NoCodeLab brand kit, and creates a 1:1 social media visual in Canva. If Canva generation fails, it returns a full visual spec in plain text: dimensions, colours, fonts, headline text, background description, rather than returning an error silently.
The execution pattern
Phase 1 runs sequentially. The Researcher goes first. Always. The Strategist cannot run without the Research Brief. This order is enforced.
Phase 2 runs in parallel. The Content Writer and Visual Designer run simultaneously once the Strategist has returned its output. This cuts total run time by roughly 40% and reduces cost, because the parallel agents are not waiting on each other.
I made this explicit in the Orchestrator's system prompt because if you don't describe the sequencing pattern in the prompt, the model will infer it, and you may not like what it infers.
The Part Nobody Tells You: Model Routing
This is where I see the most wasted money.
Most people who build multi-agent systems use the same model for every agent. It feels simpler. It isn't cheaper. And it's often not better.
Here is how I routed models across the five agents, and why:
Agent Model Reason Website Researcher Claude Haiku Structured extraction, no deep reasoning needed Campaign Strategist Claude Sonnet Core reasoning lives here; quality directly affects everything downstream Content Writer Claude Sonnet Writing quality is user-visible; Haiku shows Visual Designer Claude Haiku Tool calls only, no generative quality impact Campaign Orchestrator Claude Haiku Routing and synthesis, not creation
That routing decision keeps the estimated cost per run at approximately $0.02, broken down as:
Website Researcher: ~$0.001 (Haiku, ~3,000 tokens)
Campaign Strategist: ~$0.006 (Sonnet, ~2,000 tokens)
Content Writer: ~$0.012 (Sonnet, ~4,000 tokens)
Visual Designer: ~$0.0002 (Haiku, ~500 tokens)
Orchestrator overhead: ~$0.0003 (Haiku, ~1,000 tokens)
At a daily cap of 500 runs, that's roughly $10/day, or about $300/month at full load. That's a number I can plan around before I've written a single line of code.
I also built a hard token cap of 50,000 tokens per run into the Orchestrator. If cumulative token use approaches that ceiling, the Orchestrator returns a partial package with a clear message: "Budget limit reached. Here's what was completed," rather than truncating silently. Silent truncation is one of the most user-hostile things an agent can do.
What $15 Actually Looks Like in Practice
The total cost of my experiment, from first test run to a document I'd call production-ready, was $15 USD.
That number isn't lucky. It's the result of being methodical before I touched anything.
I had a cost model on paper before I made my first API call. I knew what each agent was expected to spend before I ran it. When something came back more expensive than the model predicted, I treated it as a signal: something in the prompt was asking for more work than the task required.
I was critical when outputs felt wrong. Not randomly critical. I looked at why they were wrong before I changed anything. Was it the system prompt? The input contract? A model that was under-powered for the task? I changed one thing at a time and observed the effect.
I was surgical in the changes I made. Vague prompt edits produce vague improvements. If I changed a constraint, I changed it precisely and tested it against the same input I'd used before.
This is what navigating Anthropic's documentation actually requires. There is a lot of it. It is detailed, it is dense, and it rewards patience. I read sections I didn't think I needed. I came back to documents I'd already read once because they made more sense after I'd hit the problem they were describing. That is how the document got built, not from a single session, but from accumulated understanding.
The Things People Skip (And Pay For Later)
There are a few sections of the ARD that most people building agents never think to write. They're some of the most valuable.
The boundary statement. I wrote explicit text for what this tool does not do, to be displayed on the landing page. The agent does not post to social media. It does not personalise visuals to the user's brand in v1. It cannot access content behind a login. It is a demonstration of what's possible, not a full marketing suite. Writing this clearly, before launch, prevents a specific kind of user frustration that no amount of post-launch support can fix.
The conversion hooks. An agent that does useful work and then disappears is a missed opportunity. I mapped four specific moments in the user journey where a conversion hook makes sense: after the Campaign Package is delivered, after a Canva visual is clicked, on the second run, and if the user re-runs for a different angle. Each hook goes to a different destination: a consulting enquiry, a course enrolment page, an email capture. Designing these before launch means they're intentional, not bolted on.
The definition of done. Not "it works in a demo." Three categories, each with a checklist: business readiness (boundary statement approved, CTA copy finalised, open decisions resolved), agent readiness (all five system prompts tested against real runs, escalation paths verified, output contracts validated), and infrastructure readiness (API keys provisioned, rate limits confirmed, token cap enforced, analytics events firing). You don't declare something production-ready until every checkbox is ticked.
The open decisions. At any point in writing the ARD, I captured decisions that hadn't been made yet, not as things to figure out later, but as explicit outstanding items with owners and deadlines. Which page on nocodelab.ai does the tool live on? Does the email capture gate go in v1 or v1.1? Is the campaign focus note optional or in scope? Eight decisions, named, owned, with a "needed by" date. Because ambiguity is where timelines and budgets go to die.
What This All Cost in Clarity
The $15 is the easy number to talk about. The harder thing to quantify is what I learned.
I learned that most agent failures are design failures. They happen upstream of the code, in the moment someone decided to skip the thinking and go straight to the building.
I learned that the Anthropic documentation rewards precision. The answers are in there, but only if you're asking the right questions, and only if you've done enough of your own thinking to understand what the answer means.
I learned that a five-agent pipeline with clear contracts, explicit escalation paths, and a sensible model routing table is actually less complex to build and debug than a single sprawling prompt trying to do everything. Complexity distributed across well-defined agents is more manageable than complexity concentrated in one place.
And I learned that the gap between "it works in testing" and "it's ready for real users" is wider than most people expect. The ARD is the thing that shows you exactly how wide that gap is before you find out the hard way.
My Goal Is Always the Same
Demystify. Clarify. De-hype.
Agents are not magic. They are structured logic with inputs, outputs, and failure modes, if you take the time to define them before you build. The black box only stays a black box if you let it stay that way.
You shouldn't have to trust blindly. You shouldn't have to burn credits discovering things that should have been designed upfront. You shouldn't need to be an engineer to think clearly about what your agent is supposed to do.
That's what the ARD is for. It's the document I wish had existed when I started. So I built it from research, from testing, from $15 of rigorous, methodical, surgical experimentation, and it's now part of Module 19 of the NoCodeLab Claude Agent Framework.
We Don't Want Anyone to Be Left Behind
If you have an idea you want to turn into a production-ready agent using Claude, get in touch.
While we're in beta, we're running free consultations: no pitch, no catch, just a structured conversation to help you get from idea to something you can actually build. We'll work through the questions the ARD is designed to answer, together.
We started NoCodeLab because we believe the people who benefit most from AI are often the ones who have the least access to the knowledge that makes it work. That's still the mission.
Drop us a message via www.nocodelab.ai/
#AIAgents #NoCodeLab #ClaudeAI